
CVE-2024-11477- 7-Zip ZSTD Buffer Overflow Vulnerability
As part of our daily job in Crowdfense, we investigate and dive deep into recently disclosed vulnerabilities to determine their exploitability and, if possible, weaponise them. We maintain a curated list of n-days (N-day Vulnerability Intelligence Feed) for red and blue teams, aiding them in conducting their operations and APT simulation scenarios.
As we routinely check for interesting vulnerabilities, especially plausible RCE ones, we stumbled upon CVE-2024-11477, a heap buffer overflow in the ZStandard (ZSTD) implementation of 7-Zip. The vulnerability is an out-of-bounds read, which, when controlled, leads to an uncontrolled heap buffer overflow. Due to the incorrect handling of ZSTD file data and an early and improper validation of an array index, the program attempted to write data beyond the bounds of a memory buffer.
The attack vector involves using 7-Zip to decompress a specially crafted file. 7-Zip versions 24.06 and 24.05 were found to be vulnerable.
Technical Details
Simply put, the compressed data in ZSTD consists of literals and sequences. The literals are first processed and then used along with the data from sequences to get the decompressed results.
A sequence consists of two “commands” – a literal copy command and a match copy command.
The literal copy command consists of one “literals length” code, and the match copy command consists of one “offset” code and one “match length” code.
The literals length and match length codes are compressed themselves, particularly when the RLE mode is used to compress the main data. Practically, the values for these codes act as indices into specific tables, from which the decoded codes are obtained.
Once these codes are decoded, they are utilised in the following manner: the literal copy command gives the number of literals to be copied from the data stream present in the literals section. In contrast, the match copy command gives the amount of data to be copied from the previously decoded data.
The vulnerability arises as the 7-Zip algorithm fails to do a proper bounds check on the literals length/match length code. Therefore, they can be set in a manner that forces the algorithm to read a value that is out of bounds of the corresponding tables. For reference, the following patch diffing image is taken from TheN00bBuilder’s writeup available on GitHub:
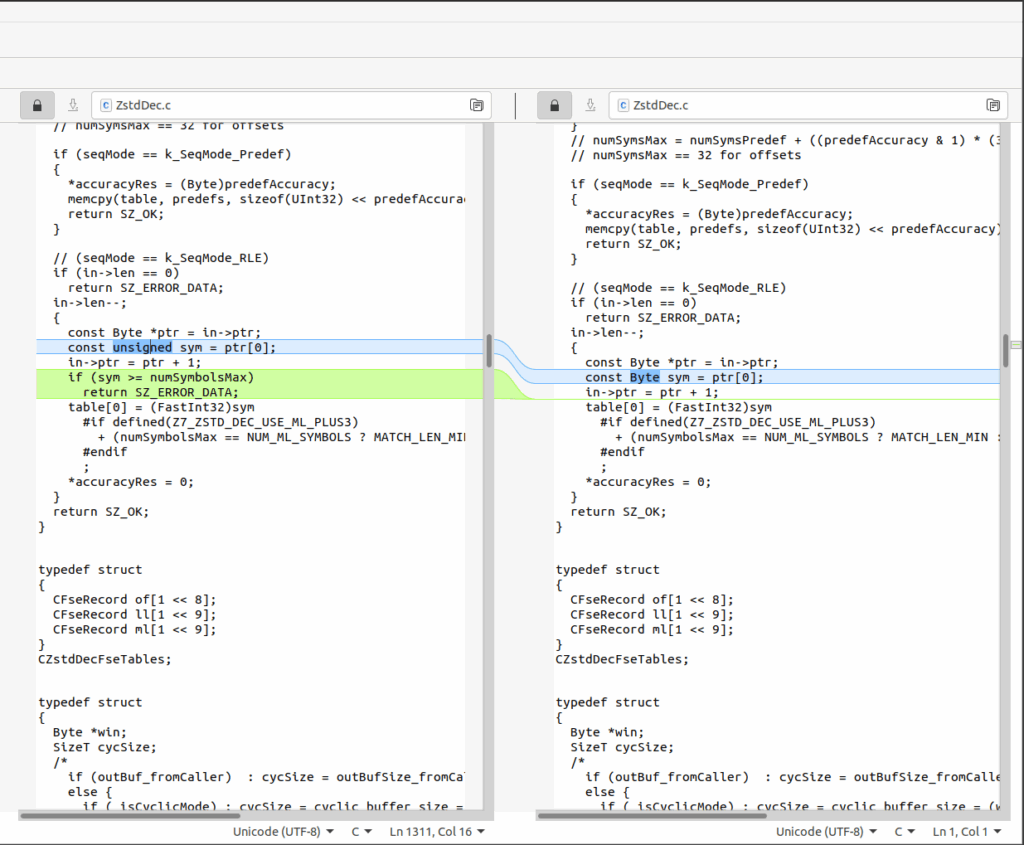
7-zip v24.07 (left) vs 7-zip v24.06 (right)
While the N00bBuilder’s writeup focuses on the vulnerability in the CopyLiterals() function caused by the value of the “literals length” code, this article will explain a similar vulnerability in the CopyMatch() function caused by the “match length” code, and will elaborate on our exploitation attempt.
Vulnerable Code
To recap, the code from the CopyLiterals() function acts in the following manner:
do {
*(QWORD *)dest = *(QWORD *)src;
*((QWORD *)dest + 1) = *((QWORD *)src + 1);
src += 16;
dest += 16;
lena = lena - 16;
}
while (lena);
Code 1.: Code leading to buffer overflow
As can be seen from the above code snippet, the code performs at least one iteration before bounds checking the value of lena, in which the value is decremented. Therefore, if the value of lena was set to zero before the initial iteration, it would pass the bounds check for every iteration thereafter, as the value will always be decreased and will never become zero.
So, the loop will execute for a large number of times, potentially infinite times, and cause a buffer overflow while accessing the “dest” buffer.
In case of the CopyMatch() function, the code is similar, and it is much easier to pass a controlled value from the match length code. In this case, the match length code must be set to 0xfd (- 0x03), so that when the operation macthLen = macthLen + 0x03 is carried out, matchLen will be zero, and zero will be passed to CopyMatch() as second parameter.
matchLen = (unsigned __int8)state_ml; // state_ml = match_len_code_from_file + 0x03
if ( matchLen >= 0x23uLL )
{
--TRUNCATED--
}
--TRUNCATED--
CopyMatch(reps_0, matchLen, win, v47, v39, cycSize);
Code 2: macthLen being passed to CopyMatch()
Interestingly, setting the code to 0xfd in the file also bypasses the IF block.
However, in either case CopyLiterals()/CopyMatch(), the number of loop iterations cannot be controlled, so the buffer overflow can’t be controlled by passing special values of literals length code/match length code.
Instead, to control the vulnerability, we can try to control the size of the allocated memory and the value of the maximum amount of data to be copied. If (size of memory) < (max. data count), then it may be possible to control the application to gain further exploitation primitives.
Exploitation Attempt
The memory under consideration is allocated within the ZstdDec_Decode() function via the following lines of code.
dec->win_Base = (Byte *)ISzAlloc_Alloc(dec->alloc_Big, d);
Code 3. Allocation of memory to be used by CopyLiterals() and CopyMatch()
The size of the allocated memory is determined by the Frame_Content_Size value from the ZSTD file, assigned to p->contentSize in the ZstdDec_UpdateState() function. Then dec->contentSize is utilized in ZstdDec_Decode() to allocate memory which is passed to the CopyLiterals() or CopyMatch() functions.
unsigned n = DESCRIPTOR_Get_ContentSize_Flag3(descriptor); // Frame_Content_Size_Flag
UInt64 v = 0;
if (n)
{
n >>= 1;
if (n == 1)
v = 256;
v += GetUi64(h) & ((UInt64)(Int64)-1 >> (64 - (8u << n)));
if (info->contentSize_MAX < v)
info->contentSize_MAX = v;
info->contentSize_Total += v;
}
else
info->are_ContentSize_Unknown = True;
p->contentSize = v;
Code 4.: Calculation of memory size (p->contentSize)
ZstdDec_Decode() also assigns dec->decoder.winSize, which is used along with contentSize to initialise p->curBlockUnpackRem in the ZstdDec_UpdateState() function, which is later used as size of data to be copied in the CopyLiterals()/CopyMatch() functions.
UInt32 blockLim = ZstdDec1_GET_BLOCK_SIZE_LIMIT(&p->decoder); // this macros initializes blockLim from decoder.winSize
// compressed and uncompressed block sizes cannot be larger than min(kBlockSizeMax, window_size)
if (b0 > blockLim)
{
p->isErrorState = True; // SZ_ERROR_UNSUPPORTED;
return ZSTD2_STATE_BLOCK;
}
if (DESCRIPTOR_Is_ContentSize_Defined(p->descriptor))
{
const UInt64 rem = p->contentSize - p->contentProcessed;
if (blockLim > rem)
blockLim = (UInt32)rem;
}
p->curBlockUnpackRem = blockLim;
Code 5.: Value assignment to curBlockUnpackRem
p->curBlockUnpackRem is passed to ZstdDec1_DecodeBlock() as outLimit, which is passed to Decompress_Sequences(), and finally as rem to CopyLiterals().
Here, the idea was to get winSize > winSize_Allocate in ZstdDec_Decode(), which would potentially cause the rem value to be larger than the size of allocated memory.
But due to the following checks NOT DESCRIPTOR_Is_ContentSize_Defined in ZstdDec_Decode() and DESCRIPTOR_Is_ContentSize_Defined in ZstdDec_UpdateState(), on the value of descriptor, the desired manipulation of winSize, winSize_Allocate, p->decoder.winSize and p->curBlockUnpackRem, could not be carried out.
ZstdDec_Decode()
// (NOT DESCRIPTOR_Is_ContentSize_Defined(descriptor))
if (!DESCRIPTOR_Is_ContentSize_Defined(descriptor)
|| winSize_Allocate > winSize)
{
winSize_Allocate = winSize;
useCyclic = True;
}
ZstdDec_UpdateState()
// (DESCRIPTOR_Is_ContentSize_Defined(descriptor))
if (DESCRIPTOR_Is_ContentSize_Defined(p->descriptor))
{
const UInt64 rem = p->contentSize - p->contentProcessed;
if (blockLim > rem)
blockLim = (UInt32)rem;
}
p->curBlockUnpackRem = blockLim;
Code 6.: Checks in ZstdDec_Decode() and ZstdDec_UpdateState()
Conclusion
Despite successfully identifying the overflow condition, the exploitation attempts revealed that while arbitrary overwriting beyond allocated heap memory is theoretically possible, practical control over the memory layout and the overflow’s extent is constrained by internal checks within the ZSTD decompression logic. Specifically, the winSize, contentSize, and related variables are bound by logical safeguards that render a direct manipulation via crafted inputs, unfeasible.
We do not foresee any viable exploitation paths for this vulnerability. Internal safeguards around memory allocation and bounds checking significantly limit control over the overflow, making practical exploitation highly unlikely.




